
Health Data Analytics Toolset
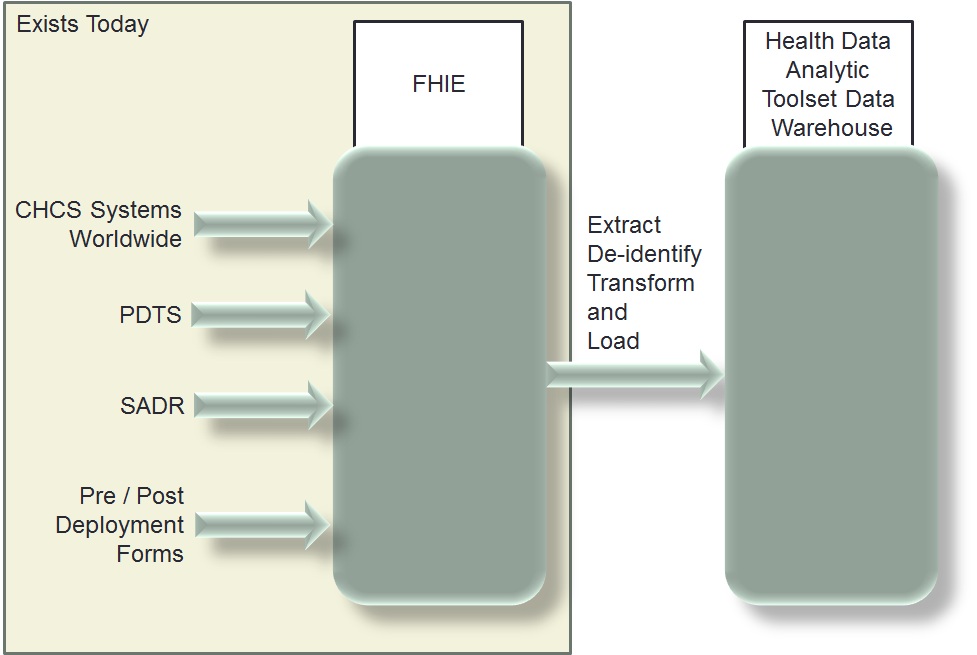
Create a clinical data warehouse designed for ad-hoc queries and research against a large de-identified MHS clinical data set.
If there were an enormous pool of de-identified health data that could be made available to researchers (primarily researchers within DoD but maybe even outside DoD), it would be possible to apply powerful modeling techniques and develop and test new hypotheses regarding how to best maintain readiness, improve population health, and reduce per capita costs.
Few organizations have so vast a collection of clinical data as MHS. With hundreds of medical treatment facilities worldwide and millions of patients, significant findings will result if clinical studies on this data become possible. Army Pharamacovigilence may find that patients who have been prescribed a specific drug have a much higher incidence of a specific disease / condition later on, or a much higher incidence of an undesirable result in a certain lab test. Researches may find that patients with a particular diagnosis / condition who received an expensive procedure did not experience better outcomes than patients with the same diagnosis / condition who did not receive the expensive procedure or perhaps something surprising like they experienced a very high incidence of heart attack later on.
This innovation uses a combination of legacy systems and infrastructure combined with currently available data analytics, display technologies, and communications. Legacy interagency data sharing programs have the MHS clinical data history on millions of patients from DoD facilities and systems all over the world including CHCS, SADR, Pre and Post deployment forms, PDTS, and the CDR. Some of these systems’ clinical data histories go back over 15 years. The data is in parsable, structured formats, mostly HL7. They also have advanced de-identification tools used to change production data into test data that can safely be loaded into test systems free of any PII / PHI, thus maintaining HIPAA compliance. These de-identification tools consistently de-identify the same real person demographics to the same fake person demographics, thus keeping the entire clinical history on a single patient intact and together. They also eliminate PII / PHI from free text fields such as comments. We could take these millions of patients’ clinical histories, de-identify them, and load them into a data warehouse that can support a wide variety of research projects.
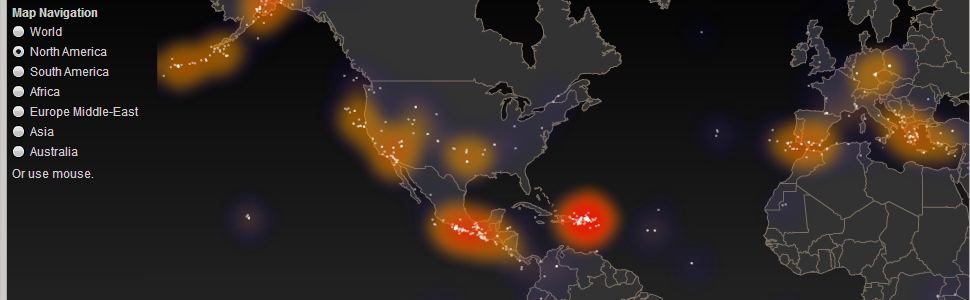
Any number of such studies or even data visualizations would become possible. As a proof of concept, this idea if awarded will include a web app displaying a heat map of the world with the MTFs displayed on it. The user will be able to enter a particular diagnosis and time span, and the heat map will display redder, larger circles where that diagnosis is occurring most often and smaller bluer circles where that diagnosis is rare. By default the heat map will simply display the number of encounters over the most recent year. But that is merely a proof of concept. The Health Data Analytic Toolset's data warehouse will be able to support a large variety of studies and research projects and visualizations.
This is a fairly standard industry practice to off load large historical sets of data into a repository designed to support analytics as opposed to ongoing operations and current transactions. Because we are very familiar with the legacy data sharing initiatives, systems, and data transfers, we can ensure that there will be no impact on the CDR or any other MHS operational systems as a result of this work and that this could be implemented for a fraction of the cost of many currently funded systems (parts and labor definitely less than one million) and in less than one year.
I am not a government employee, but Angela Hester with OASD(HA)/TMA has agreed to sponsor this submission.
0 comments